Xây dựng Trợ lý AI Tra cứu Tài liệu Tự động với n8n, OpenAI và Gemini
Làm thế nào để một AI có thể trả lời chính xác về những thông tin nội bộ hoặc các tài liệu kỹ thuật mới nhất mà nó chưa từng được huấn luyện? Câu trả lời chính là RAG (Retrieval-Augmented Generation).
Bài viết này sẽ hướng dẫn bạn cách xây dựng một hệ thống RAG tự động hoàn toàn bằng n8n, sử dụng OpenAI làm bộ não điều khiển và Google Gemini để xử lý dữ liệu, giúp bạn biến kho tài liệu trên Google Drive thành một "bộ não" số thông minh.
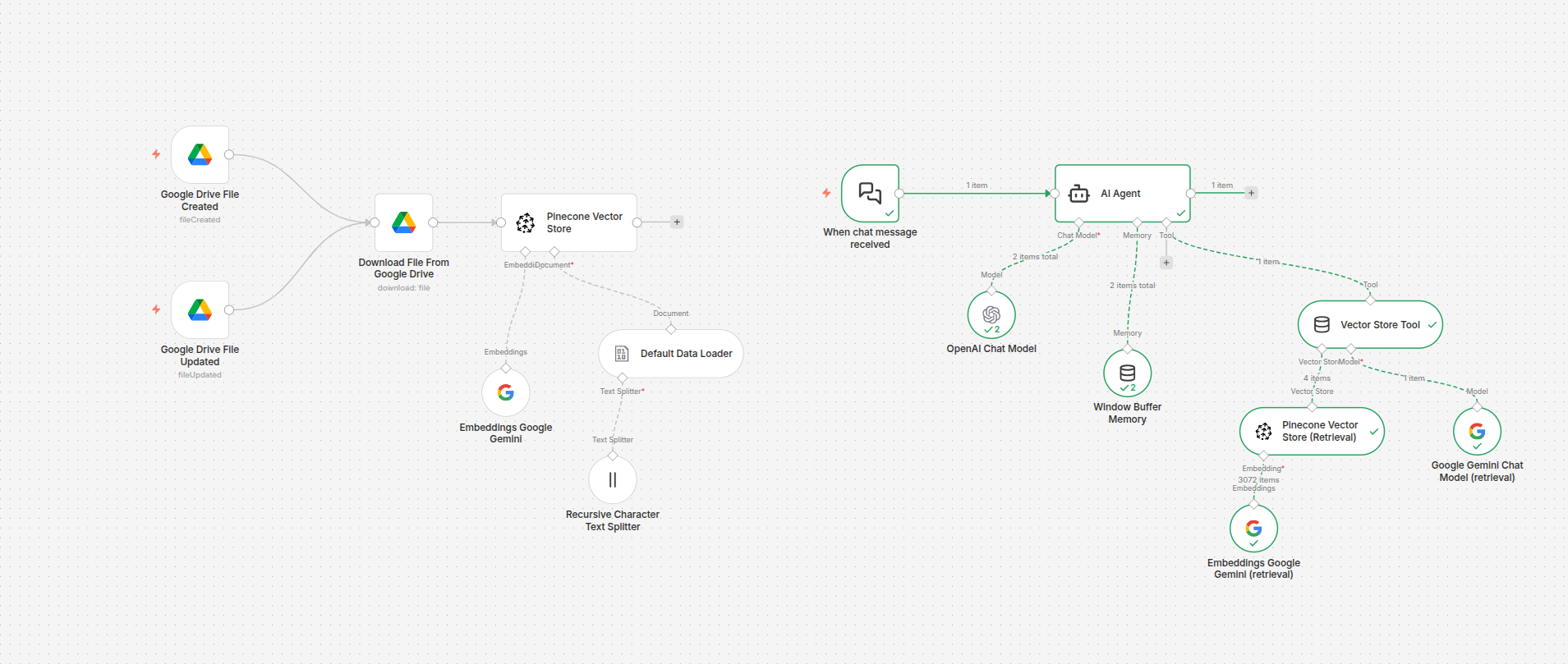
1. Phân tích Quy trình RAG trên n8n
Dựa trên sơ đồ thực tế, hệ thống được cấu thành từ hai quy trình phối hợp nhịp nhàng:
Luồng 1: Tự động hóa nạp dữ liệu (Data Ingestion)
Quy trình bên trái sơ đồ đảm nhận việc "đọc và ghi nhớ":
- Trigger: Theo dõi các sự kiện "Google Drive File Created/Updated". Mỗi khi bạn tải lên một tài liệu mới, quy trình sẽ tự khởi động.
- Embeddings Google Gemini: Sử dụng mô hình nhúng của Google để chuyển đổi văn bản thành các dãy số (vector) mang ý nghĩa ngữ nghĩa.
- Pinecone Vector Store: Lưu trữ các vector này vào bộ nhớ dài hạn, cho phép AI tìm kiếm thông tin cực nhanh sau này.
Luồng 2: Trợ lý AI điều khiển bởi OpenAI (Query Pipeline)
Quy trình bên phải là giao diện tương tác với người dùng:
- AI Agent: Đóng vai trò "đàn trưởng", sử dụng OpenAI Chat Model (như GPT-4o) để tư duy, lập kế hoạch và trả lời câu hỏi.
- Vector Store Tool: Một công cụ kết nối trực tiếp với Pinecone, giúp AI Agent có thể "tra soát" tài liệu trước khi trả lời.
- Google Gemini Chat Model (Retrieval): Hỗ trợ đắc lực trong việc trích xuất thông tin chính xác từ kho dữ liệu để cung cấp cho OpenAI.
2. Ứng dụng thực tế: Chat với tài liệu kỹ thuật phức tạp
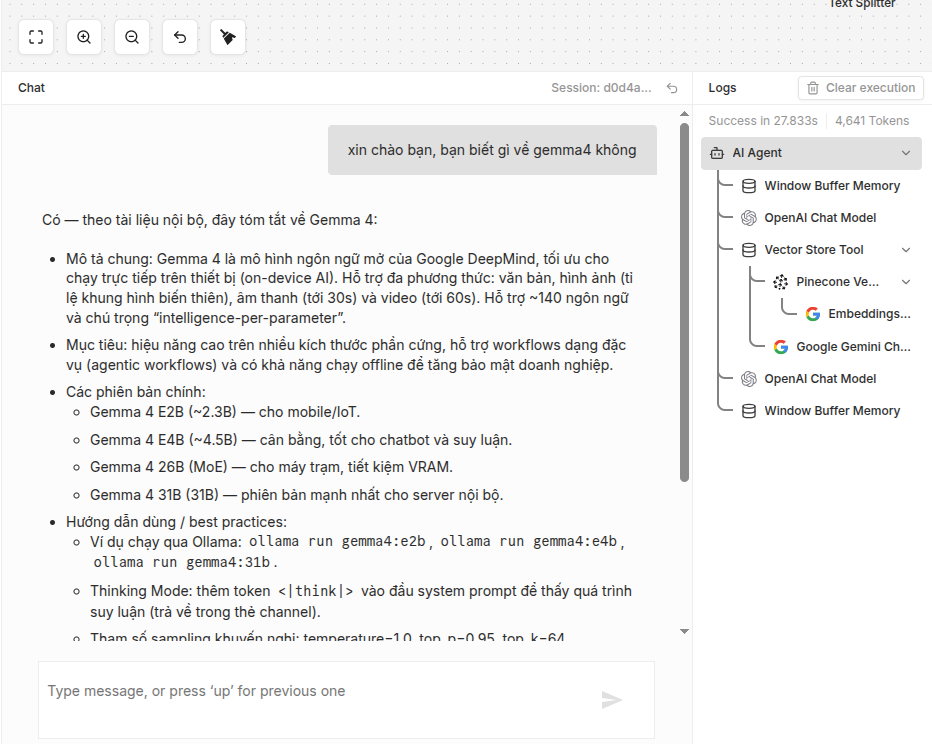
Trong sơ đồ minh họa, chúng ta thấy một ví dụ điển hình: Tra cứu thông tin về Gemma 4.
Mặc dù các mô hình AI có thể chưa biết rõ về những cập nhật mới nhất của Gemma 4, nhưng nhờ hệ thống RAG này, nó đã:
- Truy tìm trong Pinecone các đoạn văn bản về Gemma 4 (phiên bản E2B, 31B, cơ chế Thinking Mode...).
- Tổng hợp dữ liệu và trả lời bằng ngôn ngữ tự nhiên cực kỳ chi tiết.
3. Tại sao sự kết hợp này lại mạnh mẽ?
- Sự thông minh của OpenAI: Sử dụng OpenAI làm Agent giúp hệ thống hiểu ý định người dùng cực tốt và xử lý ngôn ngữ tự nhiên mượt mà.
- Sức mạnh Embedding của Gemini: Gemini xử lý việc hiểu ngữ nghĩa của tài liệu rất hiệu quả, đặc biệt là với các thuật ngữ kỹ thuật và đa ngôn ngữ.
- Tự động hóa tuyệt đối với n8n: Bạn không cần phải chạy code thủ công để nạp dữ liệu. Chỉ cần ném file vào Google Drive, mọi thứ còn lại n8n sẽ lo.
4. Các bước triển khai nhanh
- Chuẩn bị: Tài khoản n8n, API Key của OpenAI, Google Cloud (cho Gemini) và Pinecone.
- Thiết lập Ingestion: Kết nối Google Drive với Pinecone thông qua Gemini Embeddings node.
- Cấu hình Agent: Tạo AI Agent node, chọn OpenAI làm model và thêm Vector Store Tool để kết nối với cơ sở dữ liệu Pinecone đã tạo.
- Thử nghiệm: Chat trực tiếp để kiểm tra khả năng trích xuất thông tin của AI.
5. Kết luận
Hệ thống RAG tự động trên n8n không chỉ giúp tiết kiệm thời gian mà còn đảm bảo AI luôn được cập nhật thông tin mới nhất. Bằng cách kết hợp linh hoạt giữa OpenAI và Gemini, bạn đã tạo ra một trợ lý AI mạnh mẽ, có khả năng "đọc hiểu" mọi tài liệu mà doanh nghiệp bạn sở hữu.